
Cloudera annuncia la disponibilità generale del nuovo DataFlow Designer per tutti i clienti di CDP Public Cloud.
I data leader oggi sono chiamati non solo a elaborare strategie per ottimizzare l’utilizzo dei dati, ma anche a risolvere il problema di gestire fonti di dati disparate, eterogenee e in rapida espansione, ottimizzando i costi e garantendo la sicurezza e la governance dei dati, in un contesto di crescente domanda di dati da parte delle aziende e di necessità di reagire a flussi di dati sempre nuovi, in maniera tempestiva e coerente, per trasformare i processi di business. Allo stato attuale, per soddisfare queste esigenze le organizzazioni continuano a distribuire dati da più fonti verso un maggior numero di destinazioni rispetto al passato. La conseguenza è una crescente complessità che può diventare presto difficile da contenere, con i team IT da un lato, impegnati a soddisfare le richieste arretrate, e le line of business dall’altro, che creano workaround non ottimali e pipeline non corrette, senza applicare gli standard di governance dei dati o i protocolli di sicurezza. Quanto più aumentano queste pipeline eterogenee, tanto più crescono i rischi e i danni da riparare. Una marcata presenza di pipeline non autorizzate, infatti, impedisce di avere visibilità sull’entità dell’esposizione a una violazione di dati, ad esempio, riduce notevolmente la qualità dei dati per la mancanza di applicazione omogenea di policy di data lineage e definizione dei dati, e rende impossibile effettuare verifiche sui cluster di dati distribuiti. La soluzione ideale per i data leader è rappresentata dal self-service, che offre un equilibrio tra flessibilità dell’utente finale e controllo centralizzato. Per quanto riguarda le pipeline di dati, il self-service fornisce agli amministratori centralizzati della piattaforma visibilità e controllo sufficienti per gestire le prestazioni e i rischi, mentre consente agli sviluppatori di inserire nuove pipeline di dati quando necessario.
Una piattaforma di pipeline di dati self-service deve quindi fornire:
· Capacità di creare flussi di dati quando necessario, senza dover coinvolgere un team di amministrazione.
· Possibilità per i nuovi utenti di apprendere rapidamente lo strumento in modo da essere produttivi.
· Possibilità per gli sviluppatori di distribuire il proprio lavoro in produzione o di consegnarlo al team operativo in modo standardizzato.
· Capacità di monitorare e risolvere i problemi delle distribuzioni in produzione.
Il self-service nelle pipeline di dati ha il vantaggio di ridurre i costi, aiutare i piccoli team di amministrazione a scalare per soddisfare la domanda, accelerare lo sviluppo e ridurre l’incentivo a ricorrere a costosi workaround. Il vantaggio delle pipeline di dati self-service per le imprese consiste nel poter sviluppare nuove soluzioni innovative basate sui dati, con al contempo una maggiore fiducia nei dati che utilizzano. Per raggiungere questo equilibrio e abilitare la funzionalità self-service, Cloudera ha introdotto DataFlow Designer. Dopo l’anteprima tecnica rilasciata a dicembre, Cloudera ha continuato a sviluppare la soluzione per integrare un vero e proprio cambio di paradigma nel processo di sviluppo dei flussi di dati. Grazie alla capacità di costruire nuovi flussi di dati, di pubblicarli su un catalogo centrale e di produrli come DataFlow Deployment o DataFlow Function, gli sviluppatori possono ora gestire l’intero ciclo di vita dello sviluppo dei flussi di dati senza dipendere dagli amministratori della piattaforma.
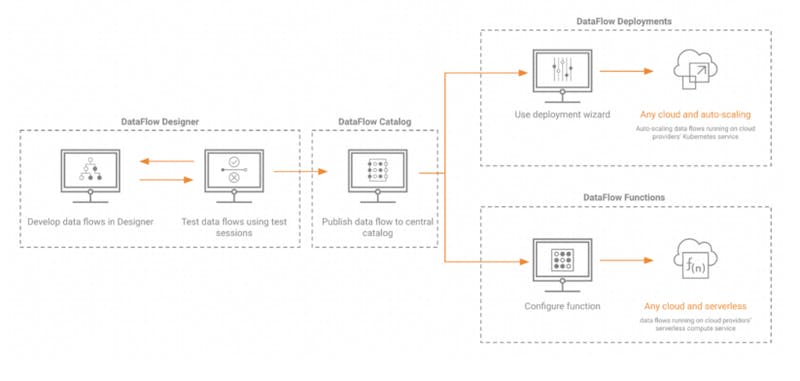
Gli sviluppatori possono utilizzare l’interfaccia utente drag-and-drop DataFlow Designer per gestire autonomamente l’intero ciclo di vita, accelerando notevolmente il processo di onboarding di nuovi dati. L’efficienza delle risorse viene massimizzata grazie alla possibilità di effettuare il provisioning automatico dell’infrastruttura proprio in quel punto specifico del ciclo, senza doverlo lasciare in funzione continuamente. Ogni fase è ora più efficiente:
· Sviluppo: Gli utenti possono creare rapidamente nuovi flussi o iniziare con i modelli ReadyFlow senza dipendere dagli amministratori.
· Test: Con le sessioni di test in un’unica esperienza utente integrata, gli utenti possono ottenere un riscontro immediato durante lo sviluppo dei flussi, riducendo i tempi legati alla rielaborazione dei flussi causati da definizioni non adeguatamente configurate per la distribuzione.
· Pubblicazione: gli utenti hanno accesso a un catalogo centrale dove possono gestire più facilmente il versioning dei flussi.
· Distribuzione: Gli utenti possono lavorare da modelli di deployment e configurare rapidamente parametri, KPI da monitorare, ecc.
· Costi: i clienti possono risparmiare sui costi dell’infrastruttura grazie a una footprint molto più leggera nel ciclo di vita della pipeline di dati, offrendo ai team di amministrazione visibilità e controllo