
Sempre più aziende si trovano ad affrontare una duplice sfida: gestire volumi di dati in continua crescita e proteggere i propri asset da ransomware e downtime. L’integrazione di Cubbit con Nakivo Backup & Replication rappresenta una soluzione all’avanguardia, che offre risposte concrete a questa sfida. Questo articolo analizza come Cubbit, il primo cloud storage geo-distribuito d’Europa, potenzi le capacità di Nakivo nella protezione dei dati per ambienti virtuali come VMware, Hyper-V e molti altri. Insieme, Cubbit e Nakivo offrono una solida difesa contro la perdita di dati, migliorando al contempo la sicurezza grazie ai backup immutabili sull’object storage geo-distribuito di Cubbit.
La tecnologia geo-distribuita di Cubbit
Cubbit è il primo abilitatore di cloud object storage al mondo: fondato nel 2016 a Bologna, è oggi adottato da oltre 250 organizzazioni, tra cui giganti come Leonardo e numerose pubbliche amministrazioni.
A differenza dei modelli tradizionali che si basano su data center centralizzati, Cubbit utilizza un approccio del tutto nuovo: ogni dato viene cifrato con il protocollo crittografico militare AES-256, frammentato in più parti grazie al codice Reed Solomon e poi replicato su più sedi all’interno di un singolo Paese. Grazie a questa tecnologia unica nel suo genere, nessun file è hostato integralmente in un’unica sede, la qual cosa aumenta la sicurezza e la resilienza in maniera significativa.
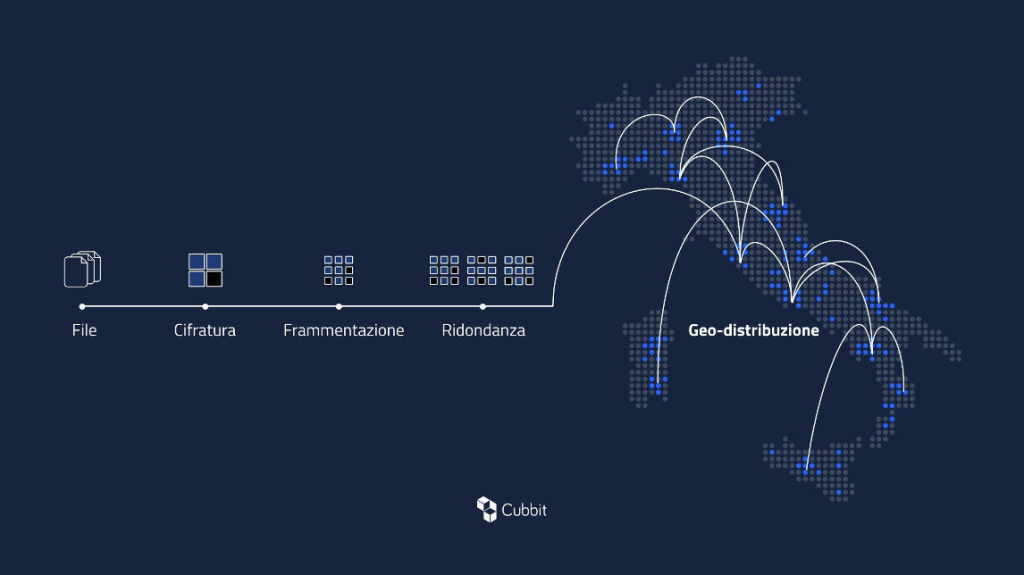
Se infatti il cloud storage tradizionale può offrire fino a 11 9 di durabilità dei dati, ossia una probabilità di perdita dei dati di 1 su 100 miliardi, Cubbit arriva fino a 15 9, ovvero 1 su 1 milione di miliardi — un aumento di sicurezza di diecimila volte rispetto agli hyperscaler.
Le misure anti-ransomware di Cubbit sono altrettanto impressionanti. Il design del sistema protegge intrinsecamente dagli attacchi informatici, assicurando che anche se un aggressore ottenesse l’accesso fisico a un nodo, si ritroverebbe solo con un puzzle indecifrabile di dati provenienti da diversi file. Inoltre, Cubbit supporta le funzioni di object lock e versioning del protocollo S3, le quali rendono i dati immutabili e consentono agli utenti di tornare a versioni precedenti dei file, senza pagare il riscatto.
Cubbit si distingue anche in ambito di sovranità digitale, permettendo alle organizzazioni di mantenere il controllo sui propri dati e di conformarsi a requisiti normativi specifici come il GDPR e il CCPA attraverso il geofencing, che limita la localizzazione dei dati a regioni specifiche.
In aggiunta, Cubbit viene regolarmente sottoposto a revisioni da parte di organizzazioni globali e detiene certificazioni in diverse aree: ISO 9001:2015 per la gestione della qualità, ISO/IEC 27001:2013 per la sicurezza delle informazioni, ISO/IEC 27017:2015 per la sicurezza nel cloud, e ISO/IEC 27018:2019 per la protezione della privacy e dei dati personali negli ambienti cloud. In aggiunta, Cubbit ha ottenuto il marchio Cybersecurity Made in Europe e la qualifica ACN (precedentemente nota come AgID). Cubbit è inoltre abilitata sulla piattaforma MePa (Mercato Elettronico della Pubblica Amministrazione).
In termini di flessibilità, Cubbit si integra in maniera nativa con il protocollo S3, supportando una serie di funzionalità che vanno dai backup automatici off-site alla collaborazione sicura e alle soluzioni di archiviazione conformi. Questa integrazione non solo migliora le capacità di protezione dei dati di Nakivo, ma fornisce alle aziende una soluzione di cloud storage versatile, sicura e intuitiva che è economicamente vantaggiosa, senza costi per l’eliminazione o il trasferimento dei dati.

Come integrare Cubbit e Nakivo in maniera semplice
Prerequisiti
Per configurare l’integrazione tra Nakivo e Cubbit, è necessario prima ottenere l’access key e la secret key dalla Cubbit Web Console o da https://console.[il-tuo-tenant].cubbit.eu. Segui le istruzioni per creare un account Cubbit e generare queste chiavi. Inoltre, è altamente consigliabile creare un nuovo bucket. Assicurati inoltre di disporre della versione 10.8 o successiva di Nakivo Backup & Replication.
Configurazione
Dopo aver attivato sia versioning che object lock sul bucket selezionato, è necessario impostare la retention su disabled, come mostrato nell’immagine seguente.
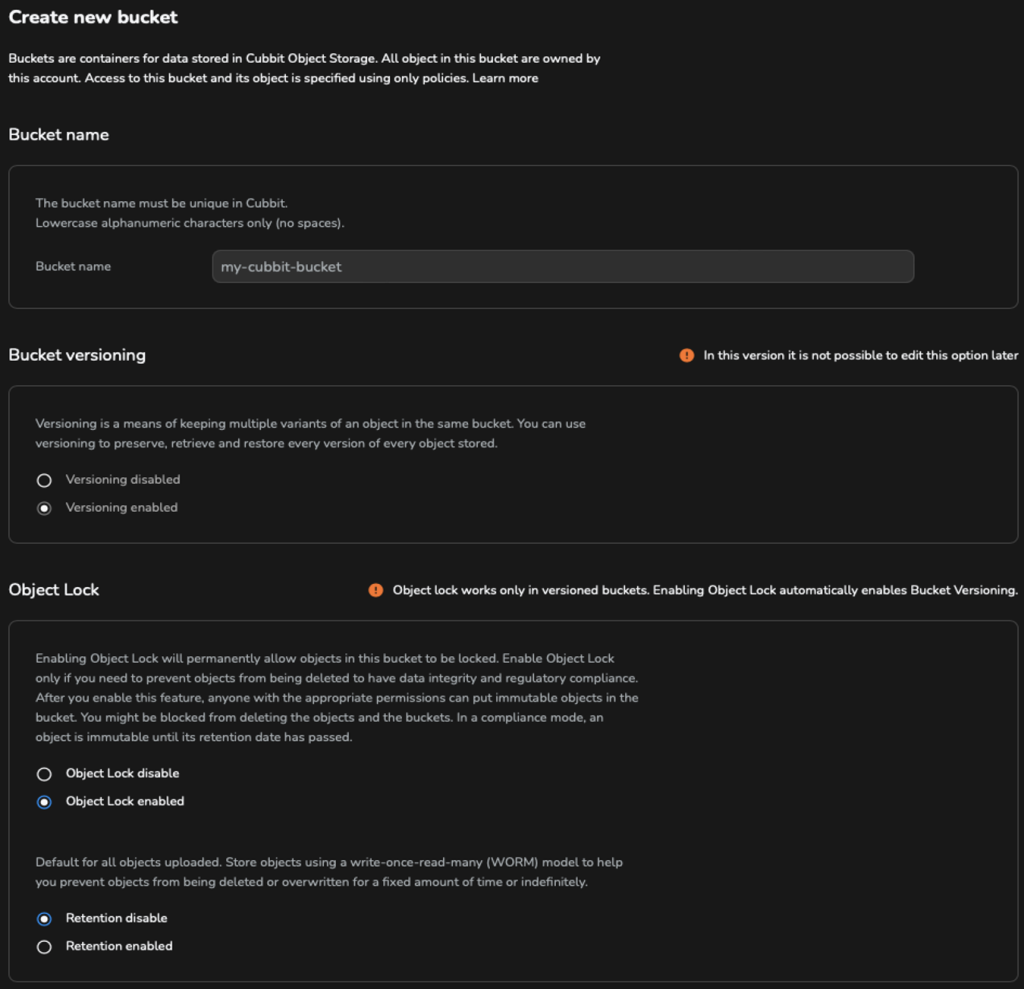
Nakivo gestirà quindi la retention policy. È fondamentale evitare l’uso di versioning senza l’attivazione di object lock (immutabilità) durante il backup su Object Storage con Nakivo. Senza l’immutabilità, infatti, aumenteranno sia le operazioni di cancellazione sia lo spazio totale utilizzato, a totale svantaggio del cliente.
Inventario
Apri la pagina di configurazione di Nakivo Backup & Replication, vai su Settings, Inventory e clicca il pulsante “+” per aggiungere un nuovo Inventory item contenente i dati da backup.
Ad esempio, per aggiungere un server VMware, segui questa procedura:
- Scegli la piattaforma Virtual;
- Seleziona il tipo di host VMware vCenter o ESXi;
- Inserisci il nome, l’indirizzo IP e le credenziali del server ESXi.
Dopo aver cliccato il pulsante “Finish”, il nuovo elemento sarà visibile nella lista.
Repository S3
Per aggiungere la Repository Cubbit S3, vai su Settings, poi su Repositories, clicca il pulsante “+” e segui questi passaggi:
- Seleziona la tipologia Cloud & S3-Compatible Storage;
- Come vendor scegli Generic S3-compatible Storage;
- Lascia il campo Assigned transporter di default (Onboard transporter) e clicca il link “Add new account” che aprirà un nuovo tab.
Nel nuovo tab:
- Come vendor scegli Storage;
- Seleziona la tipologia Generic S3-compatible Storage;
- Imposta le seguenti opzioni:
- Service endpoint: https://s3.cubbit.eu oppure s3.[il-tuo-tenant].cubbit.eu se hai un tenant personalizzato;
- Region code: eu-west-1;
- Username: la tua access key Cubbit;
- Password: la tua secret key Cubbit.
Quindi clicca su “Connect”, accetta il certificato e premi il pulsante “Save”.
Credenziali Cubbit
Torna al tab precedente e dal menù a tendina “Account” seleziona quello appena creato, mentre dal menù “Bucket” scegli quello in cui preferisci salvare i futuri backup.
Bucket di Cubbit
Per completare la creazione della repository, clicca “Next”, configura con le opzioni desiderate e premi il pulsante “Finish”.
Creazione del backup job
Per creare un backup job, vai su Jobs, premi il pulsante “+” e scegli il tipo di backup necessario, ad esempio VMware vSphere backup job.
Nel primo step (Source), puoi scegliere le macchine virtuali di cui effettuare il backup, mentre nello step “Destination” seleziona la repository Cubbit creata precedentemente.
Se il bucket ha l’object lock abilitato, attiva l’opzione “Immutable for X days” nel tab “Schedule”.
Utilizzo
Per avviare un backup manualmente, premi il pulsante “Run”, ossia il pulsante rotondo a forma di “play” all’interno del backup job.
Per ripristinare un backup precedente, premi il pulsante “Restore” con il simbolo del “download” e dal menù scegli “VM recovery from backup”. Nel primo step, seleziona la macchina virtuale da ripristinare sulla sinistra e il punto di ripristino sulla destra, poi clicca “Next” e procedi con le impostazioni preferite di “Destination” e “Options”.
Vuoi saperne di più sull’integrazione di Cubbit e Nakivo? Visita il sito web e inizia a usare Cubbit oggi stesso.