
È una tecnologia di deep learning per le applicazioni di Intelligenza Artificiale in grado di superare le attuali restrizioni di memoria della GPU quella messa a punto dai laboratori europei di Fujitsu all’interno dell’iniziativa tecnologica denominata Zinrai e dedicata all’AI.
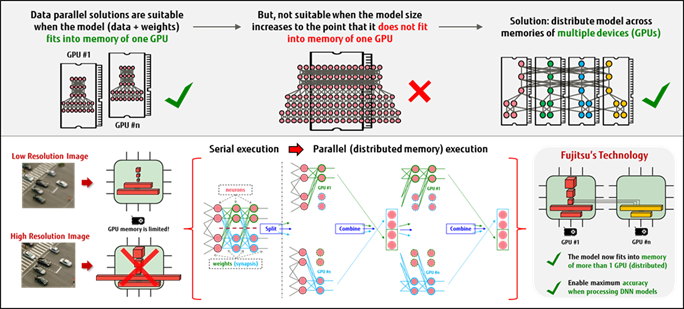
Si tratta di un nuovo e molto efficiente meccanismo di distribuzione della memoria per i Deep Neural Networks, il cui utilizzo richiede enormi risorse computazionali, che incidono pesantemente sulle infrastrutture informatiche esistenti.
Con la nuova soluzione il parallelismo del modello impiegato viene utilizzato per distribuire i requisiti di memoria DNN in modo automatizzato, trasparente e facilmente gestibile. Di conseguenza, la capacità delle infrastrutture esistenti nell’affrontare applicazioni AI su larga scala è notevolmente migliorata senza la necessità di ulteriori investimenti.
L’aumento continuo dei costi di calcolo legati ai DNN è, infatti, una sfida importante per rispondere alla quale sono necessarie reti neurali più ampie e profonde, insieme a una più raffinata classificazione delle categorie, per affrontare le sfide emergenti di AI. La soluzione Fujitsu agisce proprio distribuendo i requisiti di memoria DNN su più macchine, così da ampliare le dimensioni delle reti neurali che possono essere elaborate da più macchine, consentendo lo sviluppo di modelli DNN più accurati e su larga scala.
La nuova soluzione riesce ad ottenere questa distribuzione ottimizzata della memoria perché trasforma gli strati di reti neurali, arbitrariamente progettate, in reti equivalenti in cui alcuni o tutti i suoi strati sono sostituiti da una serie di sotto-strati più piccoli. Queste ultime sono progettate per essere funzionalmente equivalenti agli strati originali, ma sono molto più efficienti da eseguire dal punto di vista computazionale. Importante notare che, poiché gli strati originali e quelli nuovi derivano dal medesimo profilo, il processo di formazione del DNN “trasformato” converge a quello del DNN originale senza alcun costo aggiunto.
Un nuovo meccanismo di calcolo parallelo
I laboratori europei di Fujitsu hanno testato a lungo la nuova tecnologia, inclusa l’applicazione del nuovo meccanismo in «Caffe», un framework open source di deep learning ampiamente utilizzato dalle comunità di ricerca e sviluppo in tutto il mondo. La soluzione ha raggiunto un’efficienza di oltre il 90 per cento nella distribuzione della memoria nel momento in cui vengono trasformati gli strati completamente collegati di AlexNet su più GPU NVIDIA. Come tecnologia indipendente da hardware, ha la capacità di sfruttare la potenza computazionale di entrambe le unità di elaborazione convenzionali e di acceleratori hardware in fase di sviluppo, inclusi NVIDIA GPU, Intel Xeon Phi, FPGA, ASIC e altri, o qualsiasi altro hardware alternativo specificamente adattati per aumentare l’efficienza computazionale nel Deep Learning.
Progressi che influenzano la nostra vita quotidiana
Esempi di applicazioni per la nuova soluzione comprendono l’analisi nel settore healthcare, ad esempio la rilevazione della retinopatia diabetica, la classificazione e l’analisi delle immagini satellitari, l’elaborazione linguistica naturale dove sono necessari modelli di deep learning su larga scala per modellare e apprendere la completa complessità del linguaggio umano, dati su larga scala relativi a dispositivi IoT, transazioni finanziarie, servizi di social network e molto altro.