
[section_title title=“Elementare Watson”: come scoprire il colpevole dei malfunzionamenti- parte 2]
L’APM indaga: ecco il colpevole e com’è stato scovato
Il fornitore dei servizi non ha permesso di estendere ulteriormente l’indagine dell’’applicazione utilizzando l’Application Aware Network Monitoring all’interno del data center e quindi ha di fatto fermato la possibilità di isolare il dominio di errore che stavano utilizzando per altre applicazioni.
Dynatrace Application Monitoring ha localizzato il problema prendendo il posto della soluzione di APM utilizzata in precedenza e abbandonata dal cliente perché non è stata capace di portare avanti l’indagine. Dopo essere stata implementata, in poche ore la soluzione Dynatrace Application Monitoring ha identificato 7 azioni da portare avanti, tra le quali l’aggiornamento XML Parser, l’ottimizzazione di Garbage Collection e l’impostazione dei Load Balancer Settings. Abbastanza facile intuire che tra questi punti, uno doveva richiamare maggiormente l’attenzione in quanto, una volta postovi rimedio, avrebbe permesso di diminuire in modo sostanziale i tempi di risposta. La funzionalità di analisi Transaction Response Hotspot ha evidenziato che molto tempo andava perso nella fase “Reflection and XML processing api”, ma chi stava sottraendo il tempo?
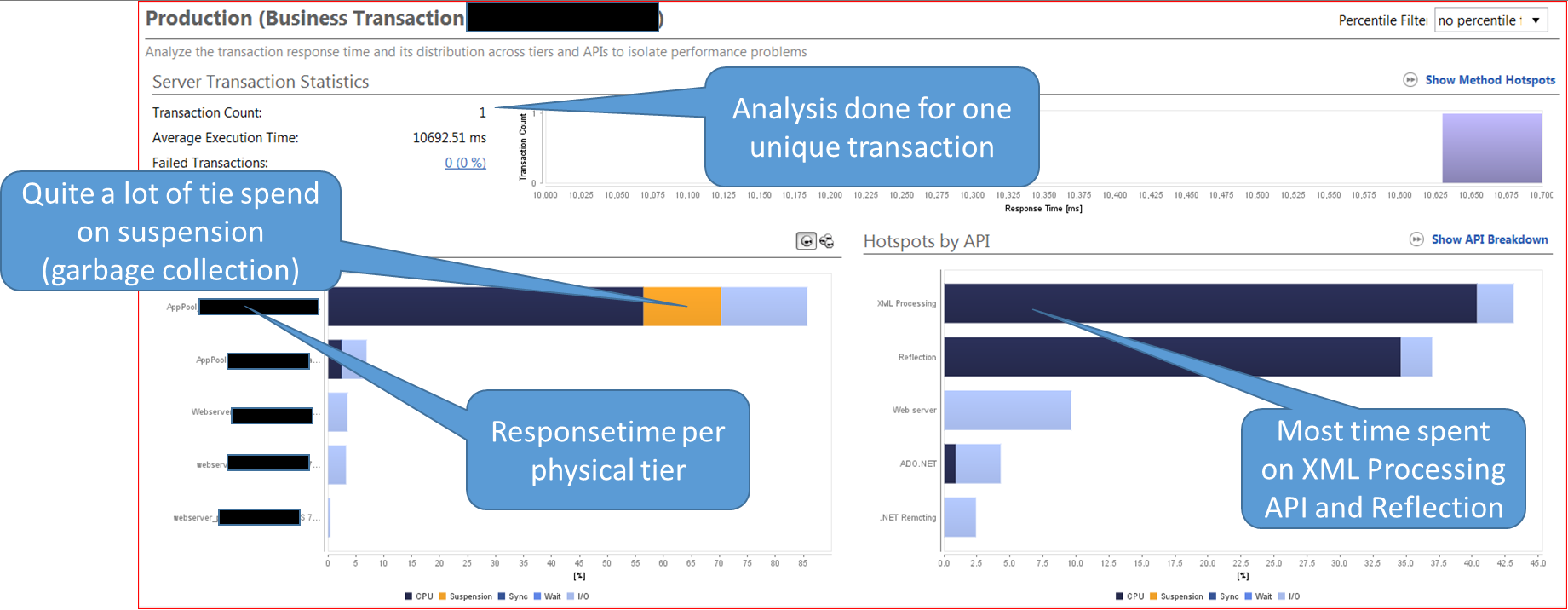
La risposta era che molto tempo veniva sprecato nel “copy method”
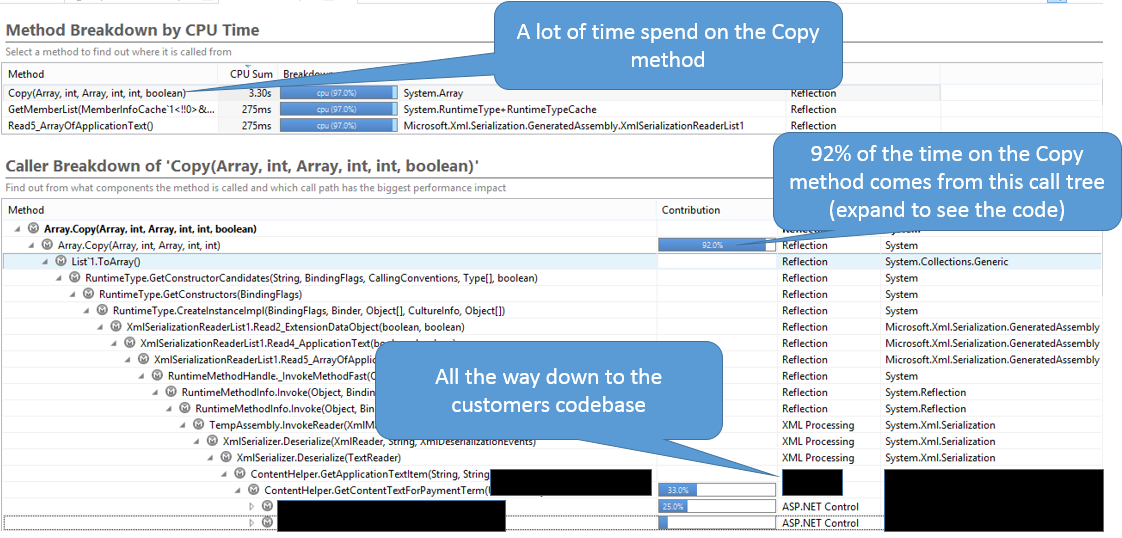
Il cerchio si chiuse: dalla produzione allo sviluppo e poi di nuovo in produzione
L’informazione è stata estratta dal sistema di produzione e mostrata a uno sviluppatore in grado di metterla rapidamente in relazione con la funzione caching che avevano implementato.
Le informazioni fornite da Dynatrace Application Monitoring dalla produzione erano sufficienti per trovare il problema e contenevano tutti i dati necessari allo sviluppatore per risolverlo. Il fatto di disporre di un numero sufficiente di dati con sufficiente granularità si è rivelato fondamentale in questo caso. Una soluzione APM che non è capace di arrivare in profondità (come quella adottata in precedenza) non avrebbe portato nella giusta direzione nel capire la causa principale effettiva. Ricordate che la singola transazione analizzata all’inizio sembrava perfetta! Avere sotto controllo tutte le transazioni aiuta molto quando non si ricerca semplicemente un errore ma dei veri e propri colli di bottiglia.
Una volta sistemato il problema, la transazione è stata provata nell’ambiente di test monitorato da Dynatrace Application Monitoring mostrando un miglioramento significativo grazie alla comparazione dei risultati fatta dalla soluzione Dynatrace analizzando le cpu. Tutto questo dimostrato che la nuova release era pronta per passare in produzione, dove fin da subito ha mostrato come era in grado di ripercuotersi sui risultati. Ecco come i miglioramenti apparivano dal punto di vista degli utenti reali finali:
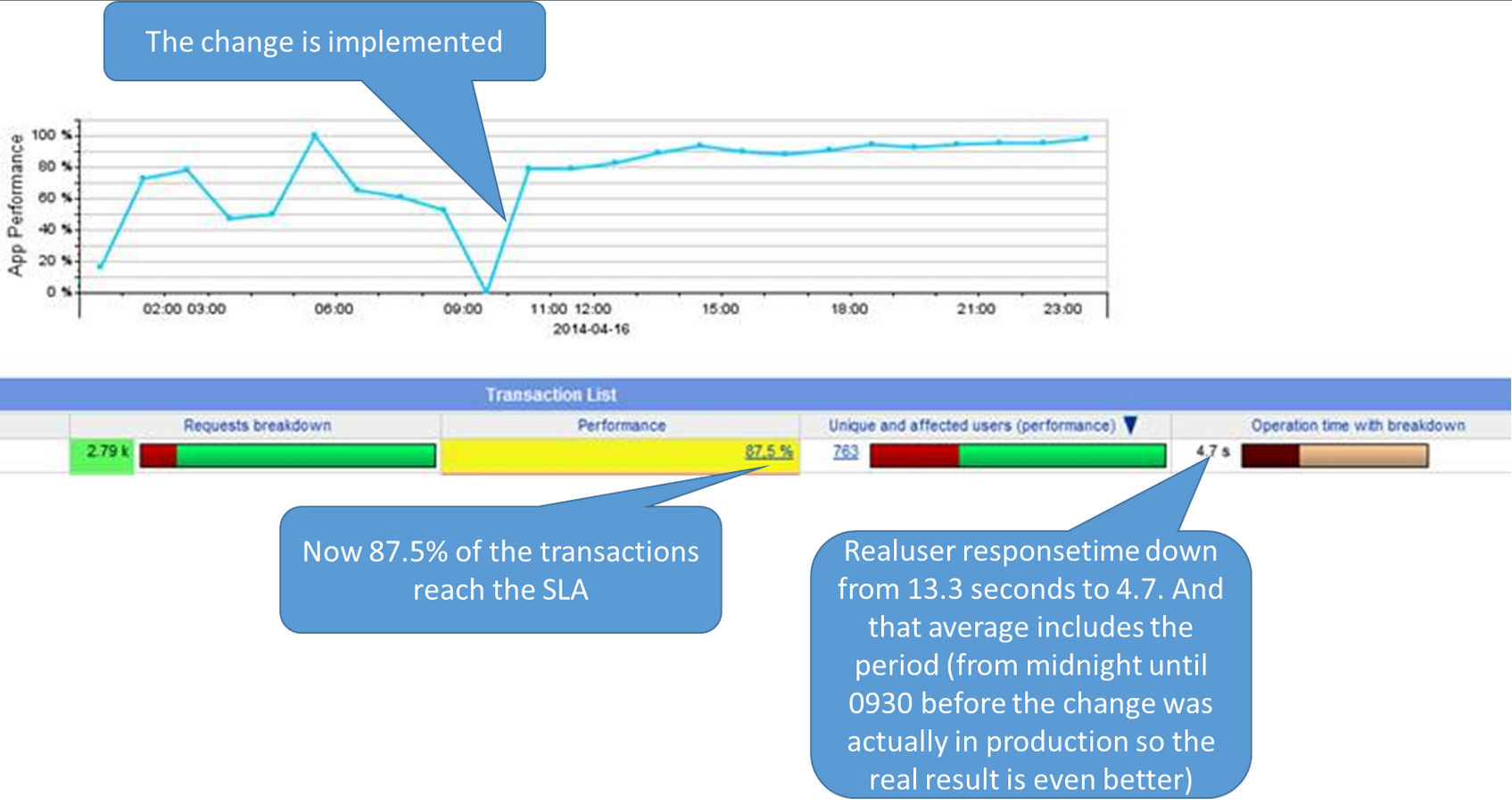
Continua a pagina seguente