
[section_title title=“Elementare Watson”: come scoprire il colpevole dei malfunzionamenti – parte 1]
A cura di Anders Lundin, Solution Specialist di Dynatrace
Lavorare nel campo dell’APM significa spesso essere sotto i riflettori quando le applicazioni hanno dei problemi. Nel nostro campo, molti seguono un approccio standard “a fasi” con poche differenze a seconda di come il ciclo di vita dell’applicazione viene implementato nei processi che nella strumentazione. Questa, invece, è la storia di un’indagine approfondita realizzata presso un cliente che ha dimostrato non solo il valore dell’APM in produzione, ma anche nei test di verifica, oltre al ruolo della collaborazione tra i responsabili del ciclo di vita delle applicazioni (dev, test e prod).
I primi sospetti
L’area commerciale di una grande compagnia di assicurazioni nel nord Europa aveva notato un calo nel business online legato alle proprie assicurazioni private. Contattato, il reparto IT, non era in grado di comprendere quale fosse la causa né addirittura di confermare l’esistenza di un problema! Tutto sembrava tranquillo dal loro punto di vista. La unit commerciale ha deciso di indagare meglio e testare la pagina manualmente con un cronometro scoprendo che i tempi di risposta di alcune funzionalità erano molto lenti. A quel punto, sono stati quindi contattati i team responsabili dell’ecommerce della pagina web mostrandogli i dubbi e le ricerche condotte manualmente.
Alla fine, la conferma è arrivata: “Purtroppo è così, ci vuole un sacco di tempo, ma ci sono tante cose che devono essere fatte durante la transazione!” La risposta non era sufficiente; l’area commerciale voleva capire quale fosse l’impatto del problema: si trattava solo della lentezza per gli utenti finali reali? Chi era interessato da questo malfunzionamento: tutti o solo specifiche aree geografiche? riguardava determinati periodi dell’anno, quando ad esempio avvenivano picchi nell’utilizzo, o accadeva sempre?
Sospetti confermati: l’indagine viene avviata
La strategia investigativa è stata condurre un monitoraggio sintetico per scoprire se il problema era visibile in Internet e da quali aree geografiche. Così è arrivata la prima conferma ufficiale dei sospetti: il tempo di risposta per la transazione di business più importante – volta a fornire il costo dell’assicurazione scelta – era molto alto, circa 12 secondi. Personalmente, avrei effettuato un refresh della pagina già dopo 5 secondi, e le ricerche mostrano che di solito la maggior parte degli utenti fa altrettanto- In questa situazione, tra l’altro, non solo gli utenti sono frustrati ma il sistema stesso è sovraccaricato.
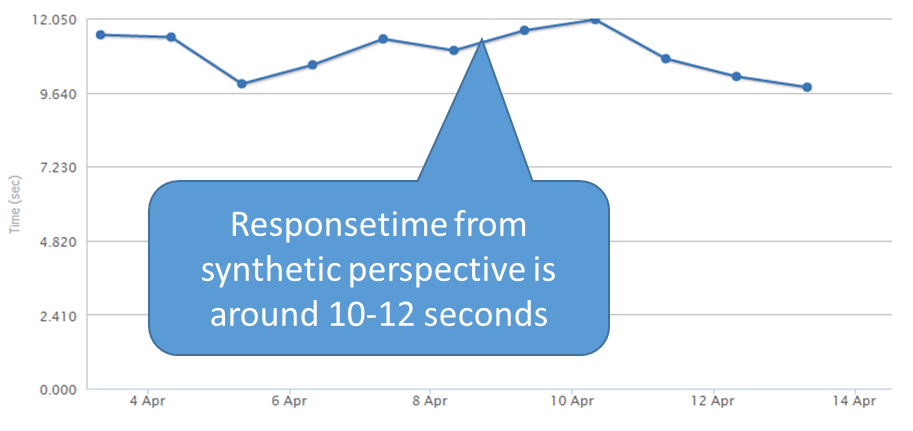
Finalmente era chiaro a tutti: c’era una criticità. Il passo successivo era capire se e quanti utenti finali fossero effettivamente coinvolti. Per fare questo l’Application Aware Network monitoring è stato distribuito sul front end dell’applicazione. La scoperta è stata “elementare”, gli utenti finali reali erano stati pesantemente colpiti dal malfunzionamento.
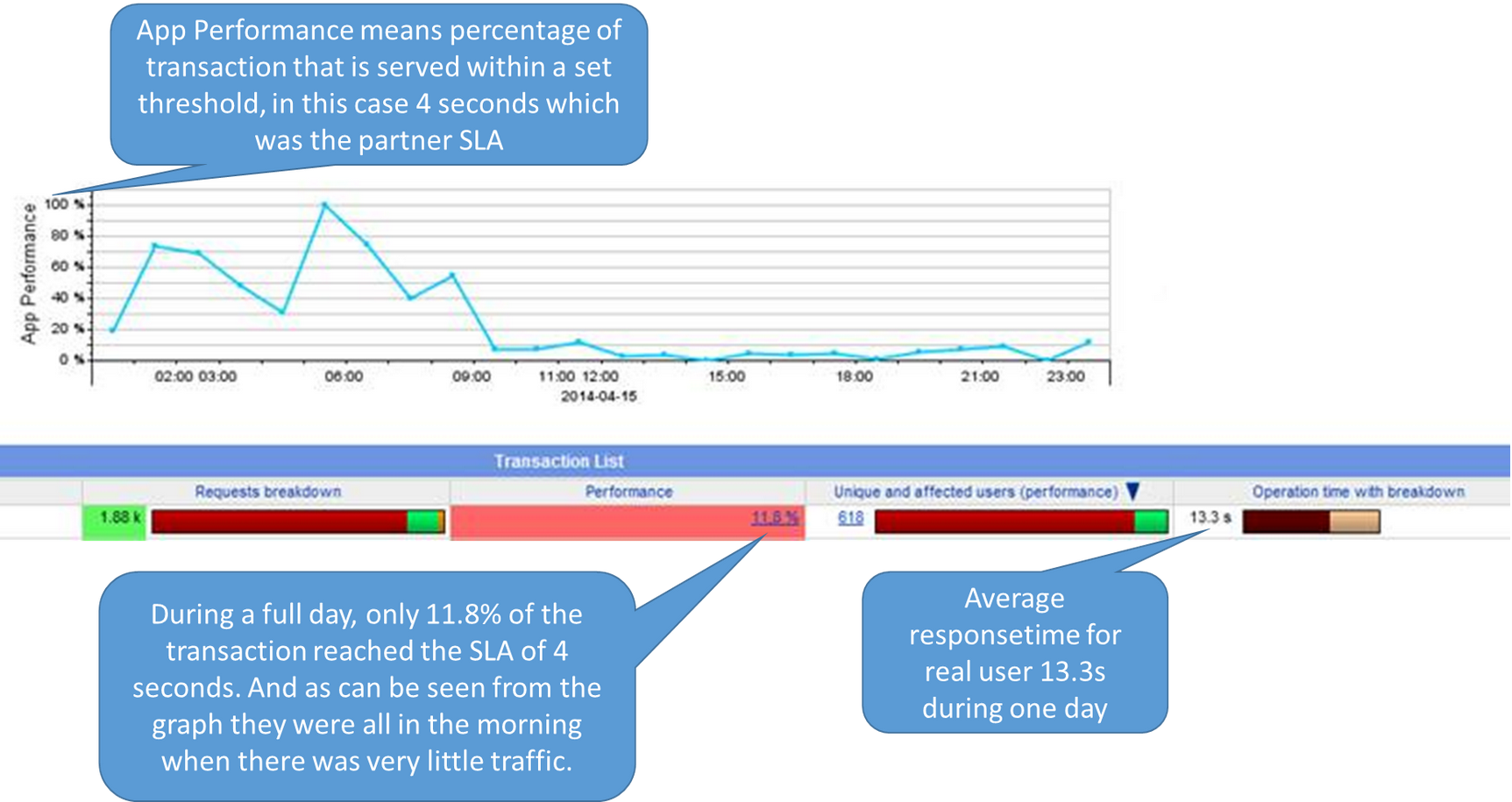
La situazione non era ammissibile. Trattandosi di un mercato estremamente competitivo, nel quale anche un singolo click fa la differenza, tempi di risposta crescenti di questo tipo non erano accettabili. Inoltre, la compagnia di assicurazioni aveva in essere in un accordo di partnership con una banca che riteneva che le transazioni volte a fornire il costo del servizio assicurativo non dovessero richiedere più di 4 secondi. Dal momento che l’adempimento a tale SLA non era mai stato misurato, nessuno sapeva di non essere in regola.
Continua a pagina seguente